揪竟...Azure Kubernetes Services 的節點能不能提供 C1000K 的能力呢?
Kubernetes is Cloud OS, Containers are Linux

既前篇文章 永續性軟體工程: 遠端抓封包實錄 有提到降低不必要網路傳輸成本可有效減少碳排放,那我繼續基於 Green Foundation 所提出的綠色軟體實踐者 (Green Software Practitioner) 當中的原則提升設備利用率 (Increasing device utilization) 來繼續延伸這個大議題
盡力地提升單台節點所能服務的量體,減少資源浪費,從這個角度看,其實就是需要來探討 Azure Kuberenetes Service 預設提供的這些節點,本體到底夠不夠提供我們在大流量和高性能計算上所需的資源和調教,這邊就從經典的百萬並行連線 C1000K (Concurrent 1000K Connections) 來做為基準來探討
[活動宣傳] CNCF Sustainability Week - Taiwan x Green Software Foundation

最近的我覺得這個題目比較在考驗 Linux 高性能調教,歡迎大家報名 2023/10/24 18:30-21:30 來吃吃喝喝探討
登入 Azure Kubernetes Service 當中的一個節點
這邊使用 v1.25 後,開始可使用的 kubectl debug 作為使用基礎,之前有些過一篇 當遇到 Distroless Container 除錯要什麼沒什麼該怎麼辦? 你的好朋友 kubectl debug 有專文解釋這個指令的效果,但今天比較特別是,對象是 Node 而非 Pod
$ kubectl version
Client Version: v1.28.1
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.27.3
# 獲得 node 名稱
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-14864487-vmss000000 Ready agent 6d14h v1.27.3
# kubectl debug node/<node name> -it --image-pull-policy=Always --quiet --image=<image name> -- <command>
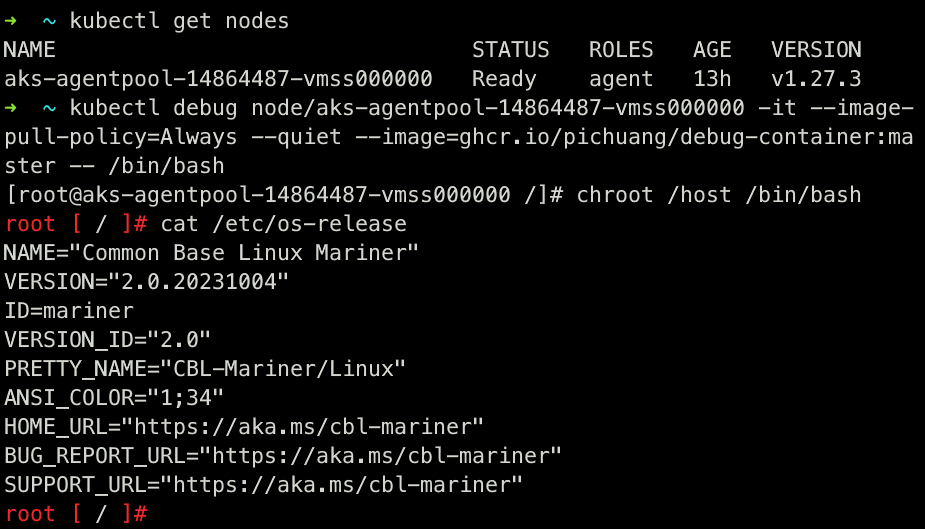
$ kubectl debug node/aks-agentpool-14864487-vmss000000 -it --image-pull-policy=Always --quiet --image=ghcr.io/pichuang/debug-container:master -- /bin/bash
# 務必要記得使用 chroot /host 切到正確的環境去
[root@aks-agentpool-14864487-vmss000000 /]# chroot /host /bin/bash
# 確保你可以看到作業系統資訊
root [ / ]# cat /etc/os-release
NAME="Common Base Linux Mariner"
VERSION="2.0.20230924"
ID=mariner
VERSION_ID="2.0"
PRETTY_NAME="CBL-Mariner/Linux"
ANSI_COLOR="1;34"
HOME_URL="https://aka.ms/cbl-mariner"
BUG_REPORT_URL="https://aka.ms/cbl-mariner"
SUPPORT_URL="https://aka.ms/cbl-mariner"
解剖 AKS Node 裡的 CBL-Mariner 作業系統
先聲明,下面的眾多操作都可以適用於任何一家的 Kubernetes 發行版和以 Linux 為基礎的節點,但當中的設定會隨著下列 3 個狀況有所差異,但基本上大同小異
- 廠商不同,如 Azure 和 Red Hat
- OS 選擇不同,如 Mariner 2.0、Red Hat CoreOS、Ubuntu 20.04
- Kernel 版本不同,如 5.15.131、5.x.x、3.11.x
AKS Environment
- Azure Kubernetes Service 1.27.3
- VM Instance: Standard D4as v5 (4 vcpus, 16 GiB memory)
- OS: CBL-Mariner 2.0,這個是 Azure 親大王子,最近還有一個 Azure Linux 親小王子出來,但還沒正式用過
- CNI: Azure CNI
- (Azure 限定) 有使用 UDR 強制控制 Egress 方向
1. CPU 相關
a. Hardware
#
# CPU
#
# 查詢 CPU 型號
# Standard D4as v5 (4 vcpus, 16 GiB memory)
# https://azureprice.net/vm/Standard_D4as_v5
root [ / ]# cat /proc/cpuinfo | grep "model name" | cut -f2 -d: | uniq
AMD EPYC 7763 64-Core Processor
# 查詢物理 CPU 個數
root [ / ]# cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
1
# 查詢每個物理 CPU 的 Core 數
# 若於 Azure Portal 設定 `platformsettings.host_environment.disablehyperthreading: true` 的話,則不會開啟 HT 的能力
root [ / ]# cat /proc/cpuinfo | grep "cpu cores" | uniq
2
# 查詢每個邏輯 vCPUs 的個數
# 邏輯 vCPUs 個數 = 物理 CPU 個數 * 每個物理 CPU 的 Core 個數 * 2 (預設 Azure VM 會開啟 HT,意旨預設狀況下,platformsettings.host_environment.disablehyperthreading: false)
# https://learn.microsoft.com/en-us/azure/virtual-machines/mitigate-se#linux
# 根據加總 processor 數量,故知道該 VM 為 4 vcpus
root [ / ]# cat /proc/cpuinfo | grep "processor" | wc -l
4
# https://www.amd.com/en/products/cpu/amd-epyc-7763
# Base Clock 2.45GHz, Max. Boost Clock Up to 3.5GHz
root [ / ]# cat /proc/cpuinfo | grep "cpu MHz" | uniq
cpu MHz : 2946.906
cpu MHz : 2445.427
cpu MHz : 2445.427
cpu MHz : 2445.427
主要這邊是要講有開 HT 和沒開 HT 的狀況下,vCPU 呈現會不同,而 Azure VM 預設狀況下都是會把 HT 開起來的。倘若要跑 HPC 或其他你就是要把這台機器效能榨到極限,則要把 HT 關掉,可使用 platformsettings.host_environment.disablehyperthreading=true
b. NUMA (Non-uniform memeory acces)
# numa
root [ / ]# yum install numactl -y # 預設沒有,需要裝
# 如下顯示,只有一個 NUMA Node,裡面有 4 個 vcpus 且被分配到 15734 MB 的 Memory
root [ ~ ]# numactl -H
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 15734 MB
node 0 free: 7277 MB
node distances:
node 0
0: 10
root [ ~ ]# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3
cpubind: 0
nodebind: 0
membind: 0
順便一提,雖然跟節點本身沒啥關係,針對 Kubernetes Pod 對於 CPU 的優化,除了花錢砸買更好的 CPU 以外,比較有策略或很 Kubernetes 的方式是,採用 Topology Manager 嘗試調整出最佳化 NUMA,Control Topology Management Policies on a node。現行共有 4 個策略可用: none, best-effort, restricted, single-numa-node,AKS 預設是採用 none,該功能常見於 5G / CNF 等對於 Pod 之於 NUMA 的使用效率有特別要求的場景,如 UPF 服務會出現,可參考 20221028 淺談 Azure Private 5G Core 和 Kubernetes
2. Memory 相關
#
# Memory
#
# 依據 MemAvailable 所示,這台機器有 13479504 kB 的 Memory 可用
root [ / ]# cat /proc/meminfo
MemTotal: 16112256 kB # 所有 Memory 大小, 故為 16 GB
MemFree: 7317172 kB # 完全沒到的 Memory 大小,很顯然我這台機器開太大了,太閒
MemAvailable: 13479504 kB # 實際上可用的 Memory 大小,MemAvailable <= MemFree + Active(file) + Inactive(file) + SReclaimable
Active(file): 1067108 kB
Inactive(file): 5021812 kB
Slab: 486692 kB
SReclaimable: 334712 kB
HugePages_Total: 0
# MemTotal 為 16112256 kB = 719104 kB + 15393152 kB
root [ / ]# cat /proc/zoneinfo
Node 0, zone DMA32
pages free 179568
managed 179776 # 給 DMA32 使用的記憶體空間為 702.25 MB = 719104 KB = 179776 * 4 KB
Node 0, zone Normal
pages free 1974218
managed 3848288 # 給 Normal 使用的記憶體空間為 14.68 GB = 15393152 KB = 3848288 * 4 KB
# 一個 Slab page 可用空間 32768 Bytes = 4096 Bytes * pagesperslab 8
# TCP 實際 Slab page 內有 31360 Bytes 被使用 = objsize 2240 Bytes * objperslab 14
# Slab page 碎片 1408 Bytes = 32768 - 31360
# TCP 實際占用的記憶體空間 470400 Bytes = num_objs 210 * objsize 2240 Bytes
root [ / ]# cat /proc/slabinfo | grep TCP
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
TCP 210 210 2240 14 8 : tunables 0 0 0 : slabdata 15 15 0
記憶體是不可被壓縮資源,跟 CPU 不一樣,如果 MemAvailable 真的用到 0 的狀況下,就代表你的節點記憶體真的是太小了,完全不夠分配出去,上面的 Pod 很容易有滿滿 OOM 的狀況。
如果你想要 Pod 有保障的資源可以用,你需要從 k8s 的角度去控制 cpu.request / cpu.limit / memory.request / memory.limit,可參考小弟舊文 如何科學地估算 Kubernetes 所需的資源? App 角度篇,這篇不會特別涉及,之後會講一篇由下而上的 Node 和由上而下的管理 Kubernetes 角度上的資源對照
順便一提,維持一個 Long Lived TCP Connection ,且不包含其他的資料傳輸,消耗的記憶體大約為 ~3.3 KB,若全部都是 Long Lived TCP Connection 且無實際資料運作或傳輸的話,大概就是消耗 3.3 GB 記憶體存這些資訊,可參考 Q5: 單台 C1000K 是怎麼算出來的? 預設啥都沒做的狀況下記憶體消耗為何? 的內容
3. Linux Kernel 相關
#
# Kernel Paraemters
#
root [ / ]# uname -a
Linux aks-agentpool-14864487-vmss000000 5.15.131.1-2.cm2 #1 SMP Sun Sep 24 03:38:45 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
# 下列都是 CBL-Mariner 的預設值
root [ / ]# sysctl -a
net.ipv4.ip_local_port_range = 32768 60999 # 該 VM 可使用的 Port Range,預設範圍為 32768 ~ 60999,共 28232 個 Port,可調整
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 5
net.ipv4.tcp_syncookies = 1 # 預設可防止部分 SYN Flood 攻擊
net.ipv4.tcp_tw_reuse = 2
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 65536
net.core.somaxconn = 16384
fs.file-max = 9223372036854775807 # OS Level,為 Int64.MaxValue 最大位數,十六進位0x7FFFFFFFFFFFFFFF
fs.nr_open = 1073741816 # Progess Level,需要比 * hard nofile (1048576) 大,不然會開不起來
net.ipv4.tcp_congestion_control = cubic
net.ipv4.tcp_mtu_probing = 0
net.ipv4.tcp_fastopen = 1
root [ / ]# ulimit -a
real-time non-blocking time (microseconds, -R) unlimited
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 62863
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1048576 # 同時可打開的檔案數量,Azure 提供的 CBL-Mariner 作業系統預設是 2^20 個,單台 VM 帳面預設數字是支援做到 C1000K 等級
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) unlimited
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
前陣子 CNCF 有一篇部落格 Tuning EMQX to scale to one million concurrent connections on Kubernetes 就在講如何調整節點內的 Linux Kernel 參數來達到 1 百萬 Concurrent Connections
這邊來比對一下 CBL-Mariner 預設參數跟 EMQX Linux Kernel Tuning 的差異
| sysctl | CBL-Mariner 2.0 | EMQX | Note |
|---|---|---|---|
| fs.file-max | 9223372036854775807 | 2097152 | 整個 OS 最大開檔數量 |
| fs.fs.nr_open | 1073741816 | 2097152 | 單一程序最大開檔數量 |
| net.core.somaxconn | 16384 | 32768 | 全連接佇列長度: min(tcp_max_syn_backlog, somaxconn) |
| net.ipv4.tcp_max_syn_backlog | 16384 | 16384 | 全連接佇列長度: min(tcp_max_syn_backlog, somaxconn) |
| net.core.netdev_max_backlog | 1000 | 16384 | |
| net.ipv4.ip_local_port_range | 32768 60999 | 1000 65535 | VM 可用 Port 範圍,但單純以 Server 端角度來說調這個沒啥太大用處,多半都 80, 443 為主,但當 Client 來講就有效果了,譬如說你要外連 DB 還是有的沒的外部服務之類的,這個調大會比較好 |
| net.core.rmem_default | 212992 | 262144 | TCP Recieve Windows |
| net.core.rmem_max | 212992 | 16777216 | TCP Recieve Windows |
| net.core.wmem_default | 212992 | 262144 | TCP Write Windows |
| net.core.wmem_max | 212992 | 16777216 | TCP Write Windows |
| net.core.optmem_max | 20480 | 16777216 | 緩衝區大小 |
| net.ipv4.tcp_rmem | 4096 131072 6291456 | 1024 262144 16777216 | 因為 MQ,訊息量小,可以 1KB 就發送一次 |
| net.ipv4.tcp_wmem | 4096 16384 4194304 | 1024 262144 16777216 | 因為 MQ,訊息量小,可以 1KB 就發送一次 |
| net.netfilter.nf_conntrack_max | 131072 | 1000000 | 調高 nf_conntrack_max 的接受上限 |
| net.netfilter.nf_conntrack_tcp_timeout_time_wait | 120 | 30 | |
| net.ipv4.tcp_max_tw_buckets | 65536 | 1048576 | 超過 TIME_WAIT 設定值則清除 |
| net.ipv4.tcp_fin_timeout | 60 | 15 | 調降 TCP 在 FIN-WAIT-2 的時間 |
如果要針對上述的參數進行調整,在 AKS 裡面,你需要依循 自訂 Azure Kubernetes Service (AKS) 節點集區的節點設定 進行設定,而不是直接進去用 sysctl 改數值,但目前 az aks update 沒支援 --linux-os-config
az aks create --name myAKSCluster --resource-group myResourceGroup --linux-os-config ./linuxosconfig.json
如果你是自建作業系統的話,就對 /etc/sysctl.conf 進行修改即可
4. Networking
a. Networking Hardware
#
# Networking Hardware
#
# 顯示預設網卡 eth0 支援最大的 Channel 大小和現行設定的大小
root [ ~ ]# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: n/a
TX: n/a
Other: n/a
Combined: 4
Current hardware settings:
RX: n/a
TX: n/a
Other: n/a
Combined: 4 # 用滿了,代表 RSS (Receive Side Scaling) 沒問題,在 CBL-Mariner 上已經是網路最佳化用法
# 下面的 interrupts 統一會由 irqbalance 自動控制,正常狀況下你不需要手動去維護下面的 /proc/irq/25,26,27,28/smp_affinity 設定
# systemctl status irqbalance
root [ ~ ]# cat /proc/interrupts | grep mlx5_comp
CPU0 CPU1 CPU2 CPU3
25: 14332354 0 0 0 Hyper-V PCIe MSI 3758129153-edge mlx5_comp0@pci:3ffc:00:02.0
26: 0 14 13861183 0 Hyper-V PCIe MSI 3758129154-edge mlx5_comp1@pci:3ffc:00:02.0
27: 0 17419688 12 0 Hyper-V PCIe MSI 3758129155-edge mlx5_comp2@pci:3ffc:00:02.0
28: 0 0 0 10673131 Hyper-V PCIe MSI 3758129156-edge mlx5_comp3@pci:3ffc:00:02.0
...
# 預設是使用 GRO 在 Linux Kernel 上把合併封包的事情給解決了,而非 LRO 在網卡上把合併封包的事情給解決了
root [ ~ ]# ethtool -k eth0
generic-receive-offload: on
large-receive-offload: off
b. Routing
#
# Linux Networking
#
# 顯示這台節點上的路由
root [ ~ ]# ip route
# 這邊要注意的是,其實我有設定 UDR 強制把 egress (a.k.a outbound traffic) 所有流量導到 Firewall (10.99.x.x) 上,但從路由表上會看不出來,得從 Azure Portal 上看
# 以下是 Node IP 的路由 10.0.128.0/24,Default Gateway 為該網段的第一個 IP,也就是 10.0.128.1
default via 10.0.128.1 dev eth0 proto dhcp src 10.0.128.5 metric 100
10.0.128.0/24 dev eth0 proto kernel scope link src 10.0.128.5 metric 100
10.0.128.1 dev eth0 proto dhcp scope link src 10.0.128.5 metric 100
# 以下是 Pod IP 的路由,10.0.129.0/24
10.0.129.0/24 via 10.0.128.1 dev eth0 proto static
10.0.129.5 dev azv7d24922a083 proto static
10.0.129.8 dev azv9da73473eb2 proto static
10.0.129.9 dev azv6f0c6f1ef57 proto static
10.0.129.10 dev azvaa6ccb05bb5 proto static
10.0.129.13 dev azvcdfece9bfdf proto static
10.0.129.14 dev azvf893453cbc5 proto static
10.0.129.15 dev azv1f6d5d20426 proto static
10.0.129.16 dev azvf85308aa314 proto static
10.0.129.17 dev azva9b3f83744f proto static
10.0.129.21 dev azv224fa8c56a6 proto static
10.0.129.22 dev azvbb0334487e3 proto static
10.0.129.25 dev azvca12febb7ce proto static
10.0.129.27 dev azv0867699d9ac proto static
10.0.129.28 dev azva412bba2170 proto static
10.0.129.29 dev azvd4c029379b6 proto static
10.0.129.30 dev azv9a46f9ec6ea proto static
10.0.129.35 dev azvd96d575dd35 proto static
10.0.129.36 dev azvee4ae66e969 proto static
# 下面是這台節點與 Azure 平台資源 168.63.129.16 溝通用的路由
168.63.129.16 via 10.0.128.1 dev eth0 proto dhcp src 10.0.128.5 metric 100
# 下面是跟 Azure Instance Metadata Service 溝通用的路由
169.254.169.254 via 10.0.128.1 dev eth0 proto dhcp src 10.0.128.5 metric 100
看路由表主要的目的是討論 Kubernetes Egress,也就是 Pod 從節點出去的路徑是怎麼走的。因為我使用的 CNI (Container Networking Interface) 為 Azure-CNI,而非使用 kubenet 或 overlay CNI 等,所以 Pod IP 其實就是我指派的某一段 Azure Subnet 網段,按照該路由,是可以從別的 Azure Subnet 或已開啟 VNet Peering 的服務直接摸到 Pod IP。
若你的 kube-proxy 是走 iptables 的話,其實是可以對 Node 套 iptables rule 影響上面的 Pod 路由,譬如說拿 ansible 對所有節點直接上路由,但這已經非 Kubernetes 能管控的範圍了,所以正常狀況下都不建議在不清楚不明白的狀況下進行這件事
後話
- 其實一開始我只是想要紀錄一下 AKS Node 上的一些預設參數,不知道為啥越寫越多。
- 如果你有看懂上面的內容,你會發現到其實研究 Kubernetes 就跟研究 Linux 作業系統是沒什麼太大區別的,不如說 Kubernetes 幫你抽象化了很多事情,讓你不用知道得太細,雖然變相你需要學習的就是 Kubernetes 的語言,從學習 shell 改成到 kubectl 的操作
- 看著上面的內容,所以我平時才會很常說,作業系統的穩定與否會直接影響 Kubernetes 的穩定性,滿滿地作業系統參數細節
- AKS Node 是有考慮到大部分的使用者都不會去看這些參數,調教是以 C1000K 為目標基準先幫大家調好了,所以沒特殊狀況下都可以順順用,也不太會有節點硬體+作業系統效能問題,自建的就要自己加油了
Q&A
Q1: 如何針對 Azure VM 關閉 HT 功能?
重開才會生效
az resource tag --ids /subscriptions/{SubID}/resourceGroups/{ResourceGroup}/providers/Microsoft.Compute/virtualMachines/{VM} --tags platformsettings.host_environment.disablehyperthreading=true
az vm restart -g {ResourceGroup} -n {VM}
Q2: 如何獲取該 Azure VM 的 Instance Metadata?
根據此文 Azure VM Instance instance-metadata-service,可透過以下方式獲取
root [ ~ ]# curl -s -H Metadata:true --noproxy "*" "http://169.254.169.254/metadata/instance?api-version=2021-02-01" | jq
Q3: 如果有要調整 eth0 的 channel 大小該怎麼做?
如果你是用 AKS 的使用者,基本上都不用改,預設一開始都弄好了
暫時處理方式,因為這個是暫時性設定,如果該 AKS 節點被移除了,新增節點或既有的節點並不會有這個功能
Q4: 何時會選擇把 platformsettings.host_environment.disablehyperthreading: true 參數套上去
跑 HPC 高效能計算類型的都蠻適合的,你會需要完整的核心計算能力,譬如說 EDA / 算圖 等
Q5: 單台 C1000K 是怎麼算出來的? 預設啥都沒做的狀況下記憶體消耗為何?
Linux 開檔限制主要卡 3 個點,三者缺一不可,以 CBL-Mariner 來看的話,預設值如下所列,故單台最大可開檔數量為 1048576,約 C1000K
| Level | Parameters | Value | Note |
|---|---|---|---|
| OS | sysctl -n fs.file-max | 9223372036854775807 | 當前系統最大可開檔數量 |
| Process | sysctl -n fs.nr_open | 1073741816 | 單一程序可開檔最大數量,一定要比 hard nofile 大 |
| User | ulimit -n | 1048576 | 當前使用者可開檔最大數量 |
維持 1 個 TCP Connection 約略消耗 3.3 KB 的記憶體,故假設全部 1048576 都開起來的話,保持 Long Lived TCP Connection,但都沒傳輸其他東西的話,大概就 3.3 GB = 1048576 * 3.3 KB,但這是理想值,實際上會大一點,由此可知,連線數量的多寡其實還有受限於記憶體的多寡,而非僅受上述的開檔數量限制
Q6: 如果 1048576 有 50% 活躍 TCP Connection,每個 TCP Connection 需要傳 1 KB/s 的資料,這樣網卡需要多大?
這個要算頻寬 (Bandwidth),也就是要算水管的大小,這篇有一個小弟早期常用的表 Bandwidth & Throughput
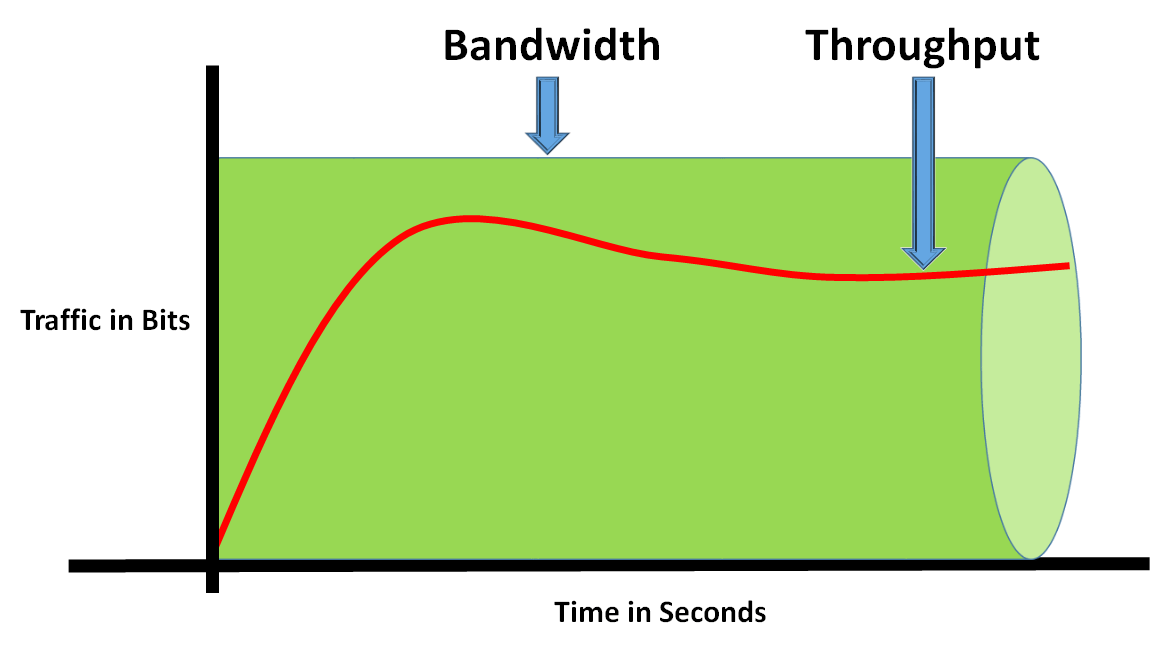
[(1048576 TCP Connection * 50% * 1KB/s) / 1024] = 512 MB/s * 8 bits = 4096 Mbps = 4 Gbps
最少你也要有 4 Gbps Bandwidth 才能承受這個量體,而 Azure VM 的網路頻寬是基於 Instance 的選擇不同,而不是看內建網卡的設定 (ethtool eth0),所以可從 Dasv5 和 Dadsv5 系列 中的 Standard_D4as_v5 的最大網路頻寬 (Max network bandwidth) 可得知為 12500 Mbps,遠大於所需的 4096 Mbps,故這台 Standard_D4as_v5 是可以支援問題所需的資料傳輸量
此外,如果你在 AKS 集群外面有用 UDR 丟給 Azure Firewall 的話,根據 Choose the right Azure Firewall SKU to meet your needs 的比較表,你需要選擇 SKU 最小為 Standard (30 Gbps) 或 Premium (100 Gbps),而不能選 Basic,不然整個頻寬會卡在 250 Mbps
Q7: 如何調整 ulimit -n 的值?
如果你是用 AKS 的使用者,基本上都不用改,預設一開始都弄好了
如果你是自架作業系統的,就照下面的設定即可
# 如果沒特別調過的,應該都是 1024 為主,譬如像 RHEL 9.2 和 RHEL 8.8 就是這樣
$ ulimit -n
1024
# 兩者取其低
$ vim /etc/security/limits.conf
* soft nofile 1048576
* hard nofile 1048576
# 不用 reboot,登出再登入就好
$ logout; login
$ ulimit -n
1048576
Reference
- 我的内存呢?Linux MemAvailable 如何计算
- Guidance for mitigating silicon based micro-architectural and speculative execution side-channel vulnerabilities
- Azure VM Instance instance-metadata-service
- 當遇到 Distroless Container 除錯要什麼沒什麼該怎麼辦? 你的好朋友 kubectl debug
- microsoft/CBL-Mariner
- 自訂 Azure Kubernetes Service (AKS) 節點集區的節點設定 - Linux Kubelet 自訂設定
- Control Topology Management Policies on a node
- Tuning EMQX to scale to one million concurrent connections on Kubernetes
- EMQX Linux Kernel Tuning
- 如何科學地估算 Kubernetes 所需的資源? App 角度篇
- 第315期 | 什么是C10K?如何做到C1000K?
- Bandwidth & Throughput
- Green Software Practitioner - Increasing device utilization
- Choose the right Azure Firewall SKU to meet your needs