Kubernetes Probe 類型及實作方式的使用說明與小建議
最近看到一個很有趣的網站 kube-score,你把你的 Kubernetes Deployment 丟進去之後,它就會各種無情地跟你說哪裡不好。當中裡面有提到針對 Kubernetes Probe 相關的建議,剛好最近案子有需要特別精算時間,故特別寫了篇文章供大家參考。順便附上一張,從 Bing Creator 提供的 DALL.E 模型所理解到的 Kubernetes livenessProbe、readinessProbe 以及 startupProbe 視覺化的樣子,很像...左納烏能源結晶

TL;DR
- Kubernetse Probe 類型重要性排序: readinessProbe > livenessProbe > startupProbe
- 呈上,每一個 Kubernetes Probe 都有各自的 initialDelaySeconds、periodSeconds、successThreshold、failureThreshold、timeoutSeconds 以及 Probe 實作方法可以設定,並不重複
- Probe 常見實作方法排序: HTTP Probe > Exec Probe > TCP Socket Probe
關於 Cloud Native Taiwan User Group
基於 CNCF 治理規範,前陣子將社團拆分成兩個,分別是 Cloud Native Taiwan User Group 和 Kubernetes Community Days Taiwan
歡迎大家動動手加入一下 CNCF 社群會員,並且點擊加入 (Join)
另外我們 2023/06 有社群活動 CNTUG 2023/06 Meetup,需透過該系統報名,統計人數,歡迎大家參加
Cloud Native Taiwan User Group 2023/06
- Kubernetes 伸縮自如的工作負載! - Phil Huang
- Topic Scalable NATS architecture with JetStream - 何秉賢
Kubernetes 能設定的 3 種 Probe 類型
基於 Kubernetes 官方文件指出
| Probe | 功能描述 | 用途 | 使用場景 |
|---|---|---|---|
| Liveness Probe (存活探針) | 用於檢測 Pod 是否在運行狀態下 | 確保應用程序在容器內部運行,如果檢測失敗,Kubernetes 將會終止容器並重新啟動它 | 這可用於檢測應用程序的異常狀態(例如,當應用程序死掉或處於不正常狀態時),類似於電腦啟動後從外部監控 BMC 確認機器運作正常 |
| Readiness Probe (就緒探針) | 用於檢測 Application 是否準備好接受網路流量 | 當容器內的應用程序正在啟動或正在進行一些初始化工作時,可以使用 Readiness Probe。當應用程序就緒時,它將返回成功的應答,並且 Kubernetes 可以開始將流量路由到該容器。 | 持續性服務健康檢查,類似於作業系統運行正常 |
| Startup Probe (啟動探針) | 用於檢測 Pod 的啟動進度 | Startup Probe 類似於 Readiness Probe,它用於檢測容器是否正在進行啟動過程。與 Readiness Probe 不同,Startup Probe 可以在應用程序就緒之前執行多次檢測。 | App 初始化,類似於電腦啟動的時候會有 BIOS 檢查程序 |
Liveness Probe
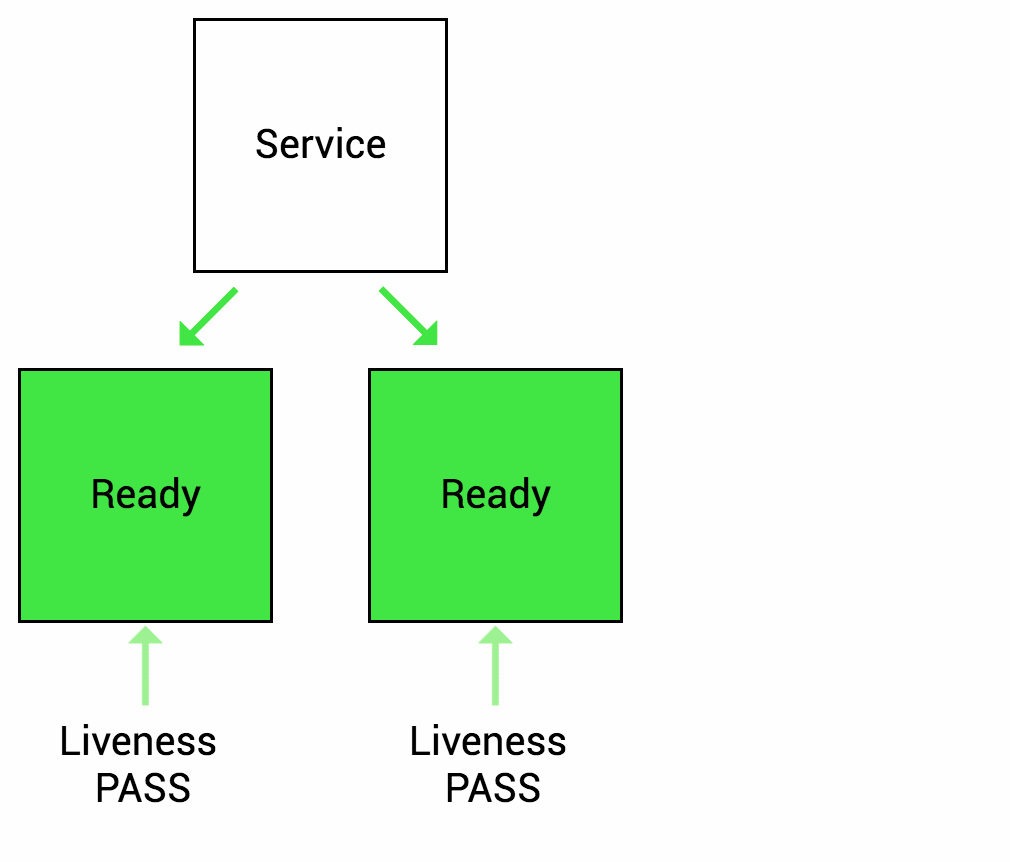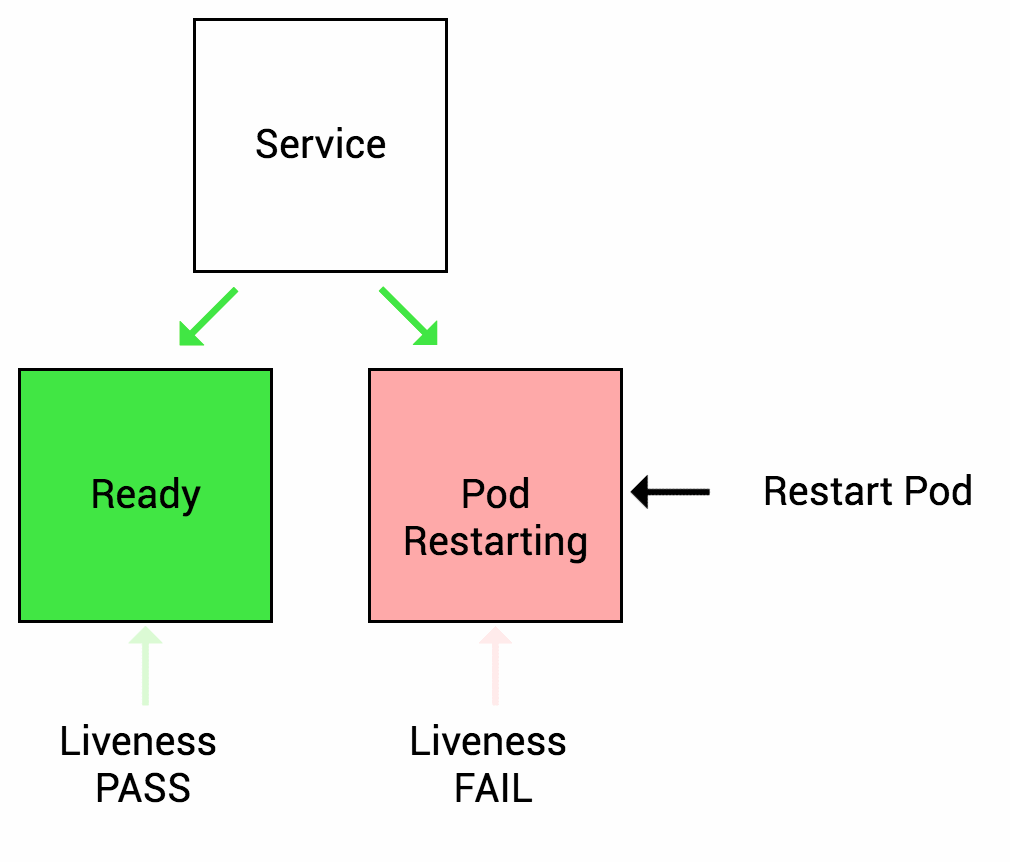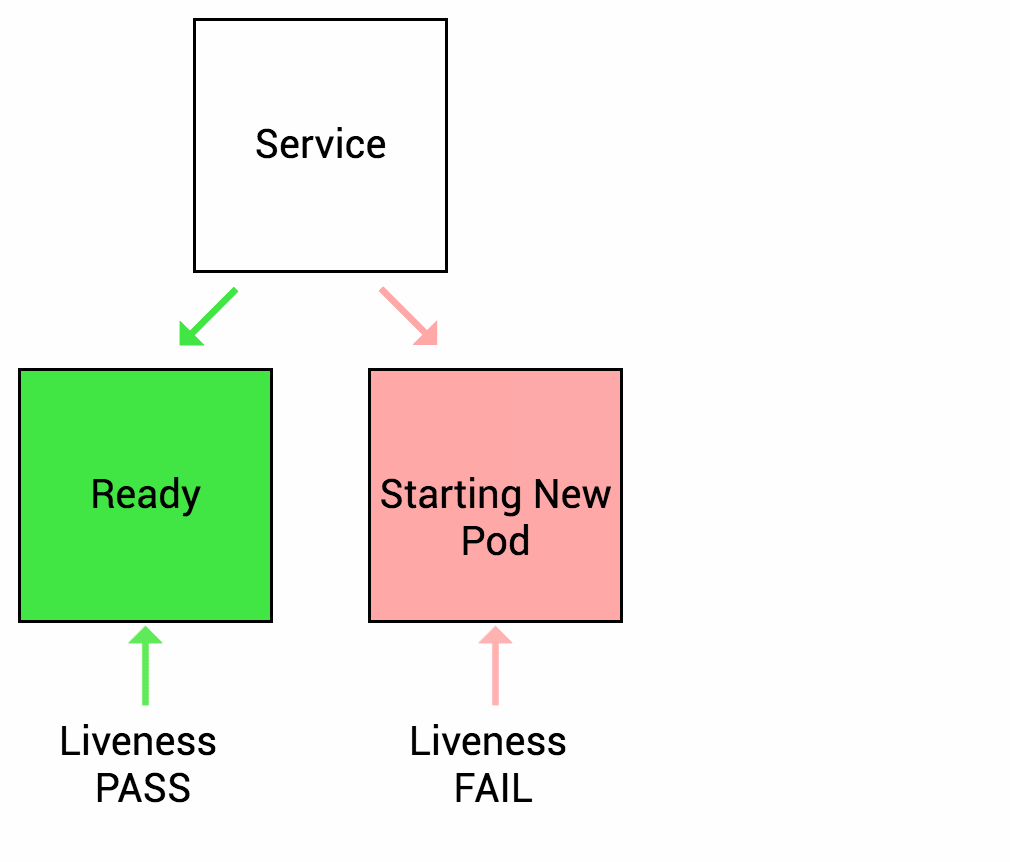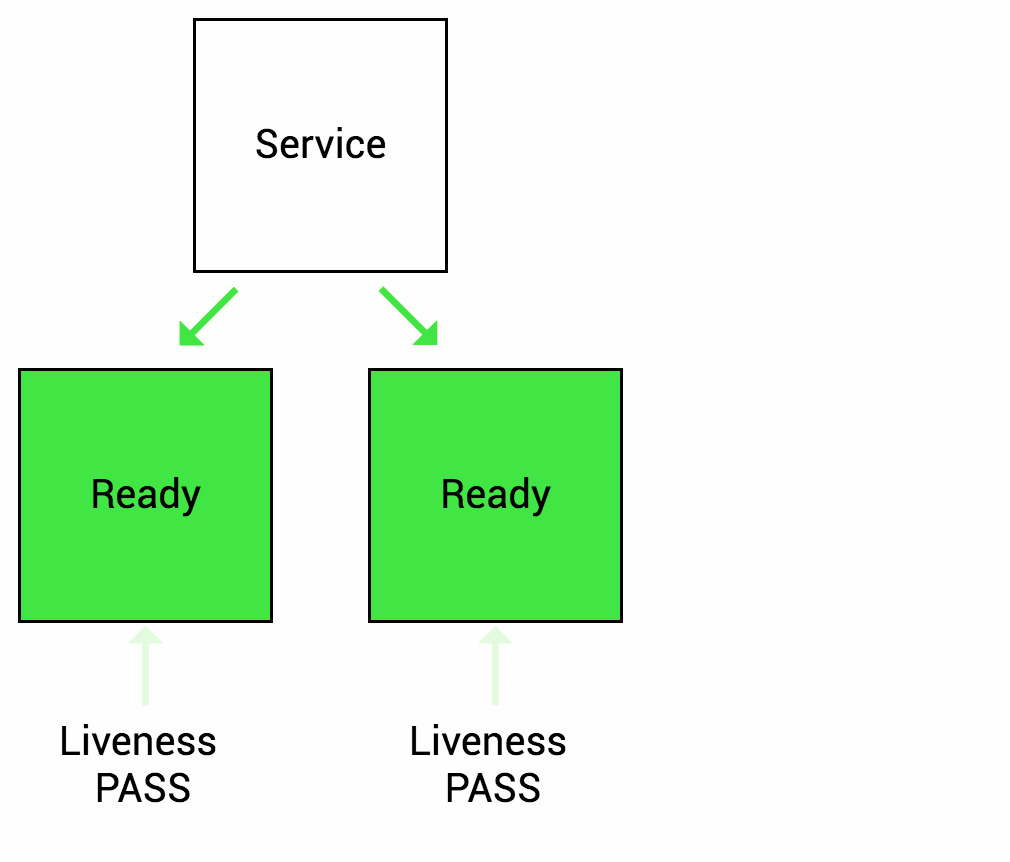
Readiness Probe
每一個 Probe 可以用下列 3 種實作方式進行檢查
HTTP Probe
最大宗的檢查方式,如果 Kubernetes 收到 HTTP Status Code 200 ~ 300 的範圍,則會標註為 Health,反之則會標註為 Unhealth
apiVersion: v1
kind: Pod
metadata:
labels:
test: http-probe
name: http-probe
spec:
containers:
- name: http-probe
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 10
readinessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 10
其實很多 Framework 或 Library 內建都有針對這個需求進行實作,可以直接使用
- Spring Boot: Liveness and Readiness Probes with Spring Boot
- .NET Core: Health checks in ASP.NET Core
- Python3: flask-healthz
Exec Probe
如果 Kubernetes 收到 Exit Code 為 0,則會標註為 Health,反之則會標註為 Unhealth
apiVersion: v1
kind: Pod
metadata:
labels:
test: exec-probe
name: exec-probe
spec:
containers:
- name: exec-probe
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 10
TCP Socket Probe
如果 Kubernetes 能建立 TCP Establish connection,則會標註為 Health,反之則會標註為 Unhealth
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
Use Cases
| 參數 | 描述 | kubernetes 預設值 | NATS-Operator | Strimzi Kafka Operator | kubernetes/ingress-nginx | mysql/mysql-operator | mariadb-operator/mariadb-operator |
|---|---|---|---|---|---|---|---|
livenessProbe.enabled |
啟用 Liveness probe | N/A | true | true | true | N/A | N/A |
livenessProbe.initialDelaySeconds |
初始化 Liveness Probe 前的延遲時間 | 0 | 30 | 10 | 10 | N/A | N/A |
livenessProbe.periodSeconds |
多久量測一次 | 10 | 10 | 30 | 10 | N/A | N/A |
livenessProbe.timeoutSeconds |
多久會超時 | 1 | 5 | N/A | 1 | N/A | N/A |
livenessProbe.failureThreshold |
成功後被視為失敗的探測的最小連續失敗次數 | 3 | 6 | N/A | 5 | N/A | N/A |
livenessProbe.successThreshold |
探測失敗後被視為成功的最少連續成功次數 | 1 | 1 | N/A | 1 | N/A | N/A |
| livenessProbe HealthCheck | Liveness Probe 探針方式 | N/A | httpGet | httpGet | httpGet | N/A | N/A |
readinessProbe.enabled |
啟用 Readiness Probe | N/A | true | true | true | true | true |
readinessProbe.initialDelaySeconds |
初始化 Readiness Probe 前的延遲時間 | 0 | 5 | 10 | 10 | 1 | 5 |
readinessProbe.periodSeconds |
多久量測一次 | 10 | 10 | 30 | 10 | 3 | 10 |
readinessProbe.timeoutSeconds |
多久會超時 | 1 | 5 | N/A | 1 | N/A | N/A |
readinessProbe.failureThreshold |
成功後被視為失敗的探測的最小連續失敗次數 | 3 | 6 | N/A | 3 | N/A | N/A |
readinessProbe.successThreshold |
探測失敗後被視為成功的最少連續成功次數 | 1 | 1 | N/A | 1 | N/A | N/A |
| readinessProbe HealthCheck | Readiness Probe 探針方式 | N/A | httpGet | httpGet | httpGet | exec | httpGet |
以 NATS-Operator 為例
基於 NATS-Operator Deployment 和 NATS-Operator 預設值,這邊因畫圖解釋方便,有調整了一下參數。故可得以下截取設定
livenessProbe:
httpGet:
path: /readyz
port: readyz
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 6
failureThreshold: 3
readinessProbe:
httpGet:
path: /readyz
port: readyz
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 6
failureThreshold: 2
Q1: 如果程式運行一段時間,然後 Kubernetes 發現 Pod 要 Pod Restarted 或者是標註 Unhealthy 最短時間為何?

首先因為程式已經運行一段時間了,所以可以省略 initialDelaySeconds 的時間
故正確的算式為
- 最短重啟 Pod 時間 = (
livenessProbe.failureThreshold- 1) *livenessProbe.periodSeconds+livenessProbe.timeoutSeconds= ( 3 - 1 ) * 10 + 5 = 25 - 最短移除 Endpoint List 時間 = (
readinessProbe.failureThreshold- 1) *readinessProbe.periodSeconds+readinessProbe.timeoutSeconds= ( 2 - 1 ) * 10 + 5 = 15
Q2: 如果程式初始運行,然後因為程式裡面沒寫好,導致 Pod Restart 開始執行的最短和最長時間為何?
需要把 livenessProbe.initialDelaySeconds 時間放進去評估
- 最短重啟 Pod 時間 =
livenessProbe.initialDelaySeconds+ (livenessProbe.failureThreshold- 1) *livenessProbe.periodSeconds+livenessProbe.timeoutSeconds= 30 + ( 3 - 1 ) * 10 + 5 = 55 - 最長重啟 Pod 時間 =
livenessProbe.initialDelaySeconds+livenessProbe.failureThreshold*livenessProbe.periodSeconds+livenessProbe.timeoutSeconds= 30 + 3 * 10 + 5 = 65
兩者時間差其實就是差一個 livenessProbe.periodSeconds 時間
Q3: 如果 Pod 從 Endpoint list 移除了一段時間後,當程式正確運行時,最短需花多少時間可以加回到 Endponit list 加回到 Kubernetes 服務的行列內?
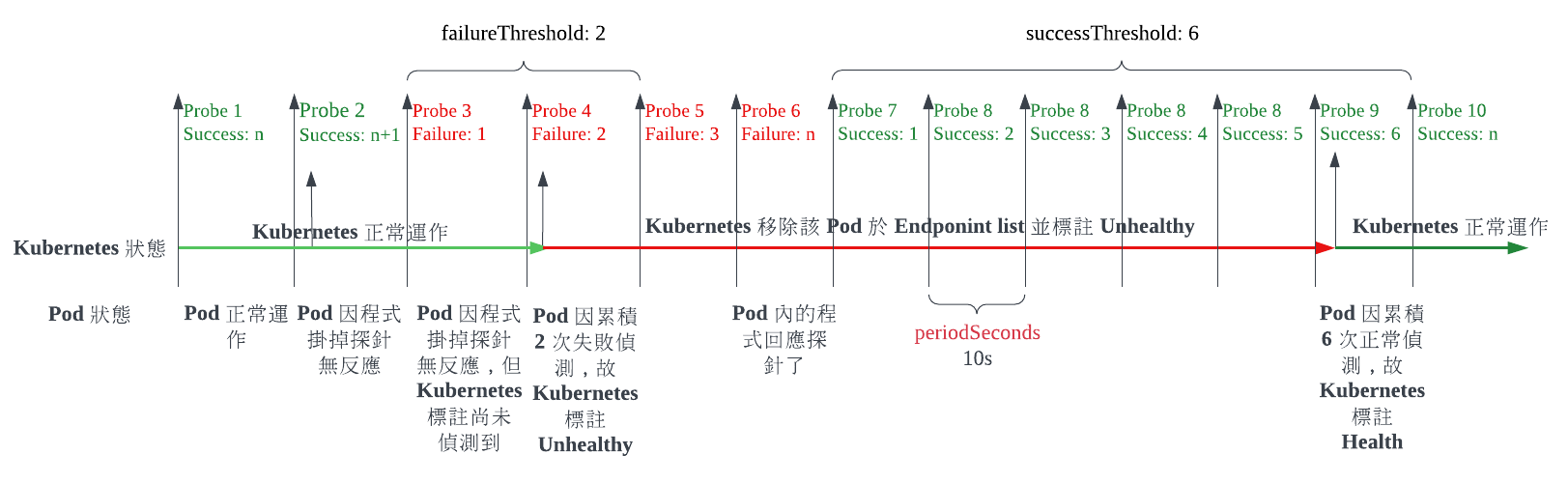
主要要看 readinessProbe.successThreshold
- 最短恢復服務時間 =
readinessProbe.successThreshold*readinessProbe.periodSeconds+readinessProbe.timeoutSeconds= 6 * 10 + 5 = 65
Q4: 如果沒設定 readinessProbe 會怎樣嗎?
有可能會在 Pod 還沒啟動的時候,流量就 Kubernetes 判斷可以被推進去,或者是 Pod 正在跑停止程序的時候,流量還是被推進去
Q5: 如果沒設定 livenessProbe 會怎樣嗎?
不會怎樣,如果你不知道要設定什麼,不用特別設定,kubelet 會根據 Pod 的 restartPolicy 進行正確的動作。如果有設定的話,盡量不要跟 readinessProbe 檢查同一個地方
Q6: 如果沒設定 startupProbe 會怎樣嗎?
不會怎樣,如果你不知道要設定什麼,不用特別設定,可以用拉長 livenessProbe.initialDelaySeconds 互換,startupProbe 的特性是只要成功一次就會換手給 livenessProbe 或 readinessProbe 進行探測
公式為 livenessProbe.initialDelaySeconds 大約等於 startupProbe.initialDelaySeconds + startupProbe.periodSeconds * startupProbe.failureThreshold,可以盡早再初始階段發現服務啟動不了
個人小建議
-
關於 initialDelaySeconds
- 針對 livenessProbe.initialDelaySeconds 特別有用
- 採用 P99 的啟動時間為主,主要是因為這個數字類同於開機需要多久時間,基本上都相當固定
- 多數有用 Framework、JVM 等都會有啟動時間的統計可以參考
- 如果真的抓不準的話,建議上 startupProbe,而不要用 livenessProbe.initialDelaySeconds
-
關於 periodSeconds
- 絕大部分的狀況下 10s 相當足夠
- 如果設定太短,有可能 Pod 只是暫時性很忙來不及回應,他就被歸類在 Failure 的狀態,如果在整體系統都是很忙的狀況下,會導致螺旋式效能下降,能者過勞
- 如果設定太長,Pod 真的有事情的時候,要很久才會有反應
-
關於 timeoutSeconds
- 最大多數抓 periodSeconds/2 或低於的數字
- 最小為 1s
-
關於 failureThreshold
- 建議 3
- 設定太高,Pod 真的壞掉的時候,導致真的要重啟或移出的時間拉的太長
- 設定太短,Pod 可能只是暫時很忙的時候,就會過早的重啟或移出,導致螺旋式效能下降,能者過勞
-
關於 successThreshold
- 建議 1
- 針對 readinessProbe.successThreshold 特別有用,livenessProbe.successThreshold 沒什麼特別效果,因為後者會把 Pod 整個重啟掉,故沒有回來的機會
- 如果 Pod 與其他服務相關服務多的話,可以數字拉大一點,
-
關於 livenessProbe
- 因為涉及到重啟 Pod 的能力,故需要保守的設定該項目
- 檢查僅需僅查自身即可,不應該涉及檢查外部相依性服務
-
關於 readinessProbe
- 因為比較偏向服務的 healthcheck,故可以比較寬鬆一點的設定