SIG Kubernetes Scability 多維度分析
前陣子剛好 Kubecon EU 2023 剛辦完,相關的影片也釋出到 YouTube - KubeCon + CloudNativeCon Europe 2023 上,共計 314 部,在當災厄林克破壞海拉魯大陸的同時,記得也要不忘持續學習
Kubernetes Communtiy Day Taiwan 2023 剩下一周可以投稿!!!
COSCUP 2023 將至,Cloud Native Taiwan User Group 跟歷年一樣我們也會於 2023/07/29 ~ 2023/07/30 內,舉辦 Kubernetes Communtiy Day Taiwan 2023
目前僅剩一周關閉徵稿,可於 COSCUP 投稿系統 進行投稿
- 正式投稿開始日期:2023 年 04 月 14 日
正式投稿截止日期:2023 年 05 月 22 日- 通知講者社群軌投稿結果:2023 年 06 月 23 日
此外基於 CNCF 社群治理規範,從 KCD Taiwan 將 Communtiy Group 單獨拆分出來,
- Kubernetes Community Days Taiwan (KCD Taiwan), 基於 Kubernetes Community Days 治理規範,網站為 https://community.cncf.io/kcd-taiwan/,為年度地區活動
- Cloud Native Taiwan User Group (CNTUG), 基於 CNCF Community groups 治理規範,網站為 https://community.cncf.io/cloud-native-taiwan-user-group/,為例行社群活動
歡迎有想要贊助、演講的個人或廠商可以依需求各別討論
Kubernetes Scability 多維度分析

Kubernetes Scalabilty 是一個多維度的問題,不單單只是用節點個數來做為衡量唯一基礎,建議參閱 Kubecon 2018 NA - Kubernetes Scalability: A multi-dimensional analysis
這邊提幾個我覺得比較重要的
# Nodes v.s. # Pods/node: Nodes 越多、Pod 於單一 Node 上越少,節點越多、Pod 於單一節點上可以越多。個人建議,通常# Pods/Node是固定的,能動的都是以# Nodes居多,所以可以固定# Pods/Node再換算總數# Services v.s. # Endpoints/Service: Service 越多、Endpoints/svc 越少,Service 越少,Endpoint/svc 可以越多。個人建議,# Endpoints/Service這個不要超過 250 或不要超過# Pods/node的上限# Service/ns: Service 越多、Namespace 越少,Service 越少、Namespace 可以越多。個人建議,# Service/ns這個不要超過 5000,會有 Pod Crash 的狀況發生
2023 SLIs/SLOs 的變化
當年 2015 的其中一條針對 API 呼叫的定義 "99% of all our API calls return in less than 1 second" 因為這句話看的人有各種不一樣的解讀,所以到了今年 2023 就換成下列 2 個更為實際的 SLI / SLO 定義,詳細可以參考這個 Git Diff
SLI
"Latency of processing mutating API calls for single objects for every (resource, verb) pair, measured as 99th percentile over last 5 minutes" "針對單一物件處理變更 API 呼叫的延遲,對於每一個(資源、動作)配對,以過去 5 分鐘內的第 99 百分位進行測量。"
這條主要有排除請求在 Queue 中的等待時間,因為沒有辦法預估 Control Plane 的負載狀況,故不考慮這部分的時間消耗
SLO
"In default Kubernetes installation, for every (resource, verb) pair, excluding virtual and aggregated resources, 99th perccentile per cluster-day <=1s" "在預設的 Kubernetes 安裝中,對於每一個(資源、動作)配對,排除虛擬和聚合資源,每個集群每天的第 99 百分位延遲應該小於等於 1 秒。"
其實還有額外官方承認和正在被討論的 SLIs/SLOs,可參考 Steady state SLIs/SLOs
- API call latency SLIs/SLOs details
- API call extension points latency SLIs details
- In-cluster dns latency SLIs/SLOs details
- DNS programming latency SLIs/SLOs details
- In-cluster network latency SLIs/SLOs details
- Network programming latency SLIs/SLOs details
- Pod startup latency SLI/SLO details
- Watch latency SLI details
可擴展性的已測試範圍
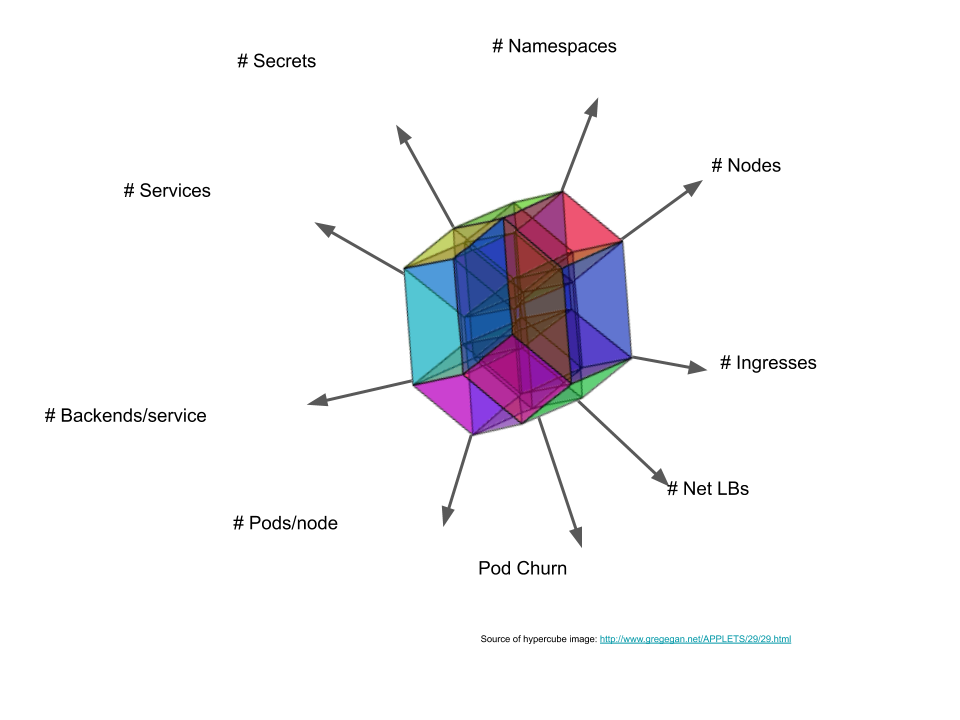
想要精確地定義可擴展性範圍 (Scalability envelope) 是不可能的,但可以抓到大約且合理的範圍,譬如 Kubernetes Scalability thresholds 所列的範圍,裡面將 scope 拆分成 2 個維度: namespace 和 cluster
依我個人理解,一般來說架構師會關心的都是下列這幾個範圍,主要會扯到網路,其他選項要爆掉的機會其實蠻低的,至於各別數字的解讀就因人而異了
| Quantity | Threshold scope=namespace | Threshold: scope=cluster |
|---|---|---|
| #Nodes | n/a | 5000 |
| #Namespaces | n/a | 10000 |
| #Pods | 3000 | 150000 |
| #Pods per node | min(110, 10*#cores) | min(110, 10*#cores) |
| #Services | 5000 | 10000 |
| #All service endpoints | TBD | TBD |
| #Endpoints per service | 250 | n/a |
| #Deployments | 2000 | TBD |
個人經驗上,上面的數字如 Nodes / Pods / Pods per node / Services 都跟要計算出網段要切多少、節點要多少個,可承載多少工作負載量很有關係,所以在規畫的時候務必要相當清楚。
實際壓測方式
主要壓測工具會用 kubernetes/perf-tests 裡面的工具:
而跑完測試則會產生測試報表可以觀察現況
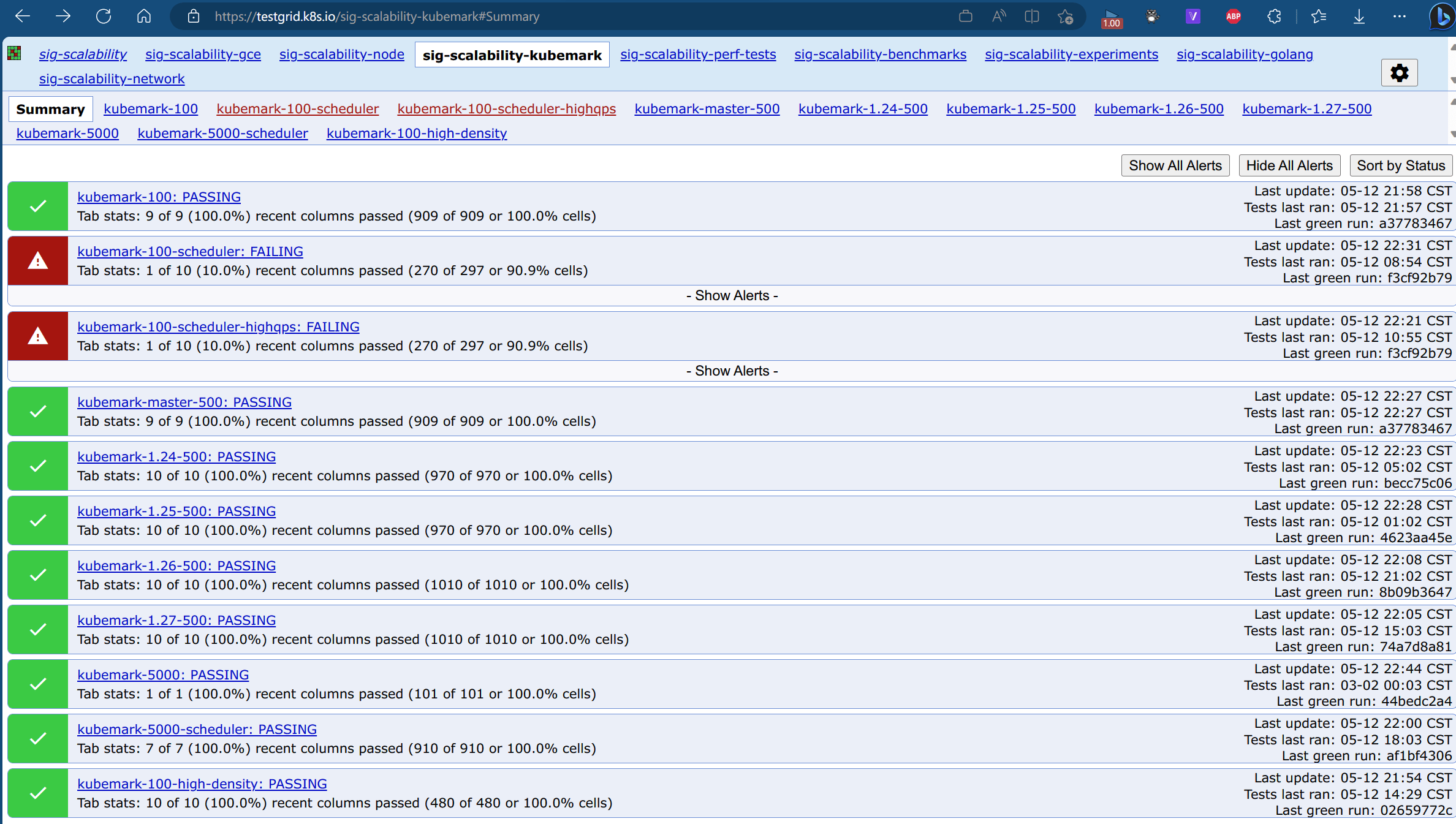
每次 Kubernetes Release 都要通過 Peformance 100 nodes / 500 nodes / Correctness 5000 nodes,測試內容都是由 kubernetes/sig-scalability/sig-scalability-periodic-jobs.yaml 來定義,而報表可以從 https://testgrid.k8s.io 這邊獲得。今年因為各家預算緊縮,現在送 Kubernetes Code 上去,預設只會跑 Performance 100 Nodes 而已,而大部分的擴展性議題都會出現在規模在超過以後 100 Nodes
預期改進方向
- Kubernetes v1.20 beta - API Priority & Faireness
- API Streaming Lists
- Gracefule shutdown
- Kube-apiserver improvements
- Improvements towards supporting higher throughput
Q&A
Q1: 與 Kubernetes SIG Autoscaling 差異是?
Note
Not to confuse with SIG Autoscaling!
SIG Scalabilty 關心 Kubernetes 整體系統的極限,如果你是負責提供 Kubernetes 安裝建置的或需要基於以 OSS Kubernetes 為基礎的自行維護版本,會需要關心 Scalability 議題 SIG Autoscaling 關心 Horizontal Pod Autoscaling / Vertical Pod Autoscaling / Cluster Autoscaling,如果你只是需要 Kubernetes 上面的程式部署,則僅需要關心 Autoscaling 議題
Q2: Kubernetes SIG Scalability 的主要任務是?
主要頁面於 Scalability SIG (Special Interest Group)
5 個主要的工作領域:
- 定義和驅動 (Define & Drive): 定義和驅動可擴展性目標
- 協調和貢獻 (Coordinate & Contribute): 改進 Performance 更接近目標
- 監控和量測 (Montior & Measure): 透過監控和量測來確保實際系統行為接近目標
- 保持和保護 (Preserve & Protect): 確保系統免受可擴展性回歸 (Scalability regressions) 的影響
- 諮詢和教學 (Consult & Coach): 透過社群協作獲得更多的使用案例和回饋經驗
Q3: Kubernetes 整體壓力測試最大的點在哪裡?
Control Plane
Q4: 測試節點 5000 是不是上限?
不是,講者說主要卡在測試成本太高,此外多數使用者對此沒有什麼特別期待,正常規畫可以以 100 Nodes 為基礎設計就好
關於用 Azure Kubernetes Service 計算 5000 個節點的計算方式,可以參考之前寫的拙作 看 OpenAI 使用鈔能力招喚 Kubernetes 7500 台節點!!!,有詳細的計算過程
Q5: 如何量測 Kubernetes 整體的效能? 第一步是?
上 Grafana + Prometheus 會是很好的起步,或者是可以從 CNCF Observability 挑出適合的工具。 若想要針對 Observability 有更深入的了解,建議可以參加 CNCF TAG (Technical Advisory Group) Observability 🔭⚙️
References
- Intro + Deep Dive: Kubernetes SIG Scalability - Wojciech Tyczynski, Google
- Intro + Deep Dive: SIG Scalability - Marcel Zięba & Wojciech Tyczyński, Google
- Kubernetes Scalability thresholds
- Scalability Special Interest Group
- Steady state SLIs/SLOs
- ClusterLoader2
- kubernetes/sig-scalability/sig-scalability-periodic-jobs.yaml
- testgrid.k8s.io
- YouTube - KubeCon + CloudNativeCon Europe 2023