如何定義 Network Latency SLOs? 4 個設計原則與百分位數解析
Note
衡量你想要監控的內容意義,不要只監控您碰巧能夠輕鬆監控的內容
Service Level Objectives (SLO) 可以讓你清楚的理解現在系統運作的狀況,但它背後的數字代表意義是需要透過一連串的數字統計和計算而得的。而最近無論是設計跨國網路,雲地混合網路,都會遇到一個關鍵元素: Latency 延遲,對於資料傳輸來說,延遲是一個很重要的指標,因此我們需要一個方法來定義這個指標,這篇文章就是要來介紹如何定義 Network Latency SLOs
4 個設計原則
- 單位必須是
milliseconds (ms) - 建議要呈現 6 個百分位數 (P, Percentile) :
P50, P75, P90, P99, P99.9, P99.99 - 除了上述的百分位數,如果要新增新的百分位數,則需要一定要
>= P50,若低於 P50 則沒有意義 - SLO Target 需要包含上述最少 2 個百分位數,其中一個必須是
P99
Network Latency SLO 常見描述
採用百分位數表示法: 於特定服務 X,百分位數 % Latency 在 特定時間區段 P 內 需要小於多少 T ms"
“Compoents X report that % of latency in PERIOD are served in < T ms”
在多數狀況來講,Latency 是越低越好 (Lower is Better),所以後面的判斷式為小於為主
百分位數解析
以下列資料集作為範例

為何要設定 P50 (中位數, Median)?
特定時間區段中,100 個數字中,從小到大進行排序,第 50% 數字,以上面 Data Set 為例,P50 =
39.15,代表 50% 的 Network Latency 在 39.15ms 以下或更小
- 適合情境: 適合看全站網路效能下降或上升,整體曲線穩定
- 不適合情境: 使用者跟你說他
現在連線很慢 - 能夠避免: 非常態分佈狀況 (Non-normal distributions) 和偏差值影響
Azure network round-trip latency statistics 其實就是一個最好的範例,下圖提供了於 2022/06 時間 30 天區段 P50 的 Latency 表現
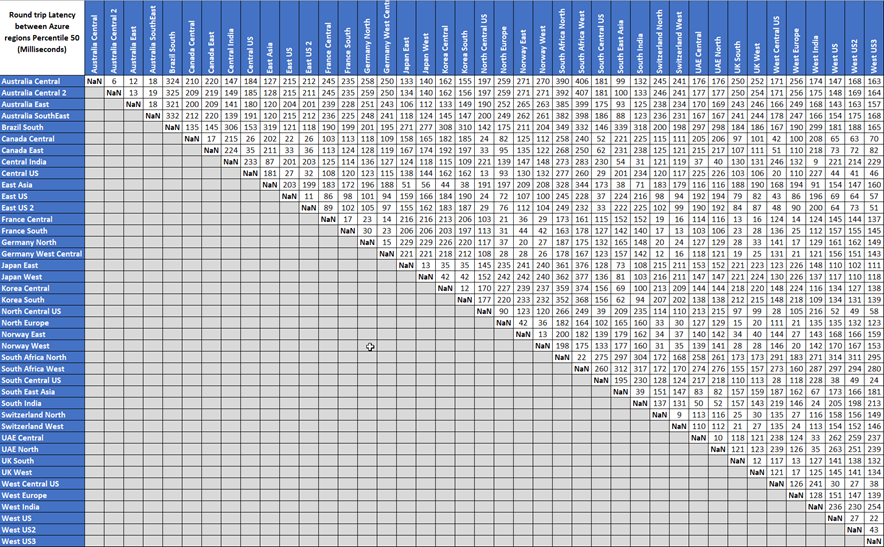
為何要設定 P99 或更高百分位數?
特定時間區段中,100 個數字中,從小到大進行排序,第 99% 的數字,以上面 Data Set 為例,P99 =
119.98,代表 99% 的 Network Latency 在 119.98ms 以下或更小
- 適合情境: 貼近使用者當下使用狀況,可以充分反映當前程式設計變化導致的影響,譬如說後端服務寫太慢或效率不好導致很慢
- 不適合情境: 想要知道全站常態穩定度如何
- 能夠避免: 常態分佈狀況 (Normal distributions) 導致忽視偏差值狀況
常見會看到 P99.9 比較適用於 Application 端,如果你是以 Infra 角度看 P99.9 的話,百分位數越高最佳化成本會超高,譬如說你想要這麼極端降低 Network Latency 和 Jitter 的話,我看大概要光纖直連,或者是中間設備都是超高檔的 Router 和 Switch 可能比較有機會辦到...對 Infra 不太現實
不要使用平均值 (Average)
Note
平均值 (Average) 不等於 P50 (中位數, Median)
平均值 (Average) 就是算術平均數,計算方式為一組數字相加,然後再除於這組數字的個數,不能反映當前狀況,因為平均值會受到極端值影響,請用中位數 (P50) 替代
舉例一個極端例子把 Fibonacci Series 列出來,算出來的平均值跟 P50 會有相當大的差距,因受到大數影響,平均值會遠大於 P50。換個白話來講,我、台灣首富、全球首富 3 位平均起來,可以買下一棟 101,相當不準確...
根據 #LatencyTipOfTheDay: Average (def): a random number that falls somewhere between the maximum and 1/2 the median. Most often used to ignore reality.,指出 Average 因介於為最大值 (MAXIMUM) ~ 中位數/2 之間

故你老闆或使用者要求你提供某某系統的運行平均狀況,正確來說應該要自行翻譯成提供某某系統的中位數 (P50) 狀況 才是比較正確
個人建議
基於 P50, P75, P90, P99, P99.9, P99.99,以 P99 為中央伍
- 如果你是偏向 Infrastructure 監控或者是偏基礎建設的 Administrator,建議可以長期追蹤 P50, P75, P90, P99 這四條的變化,因為這四條的變化,可以反映出你的基礎建設是否穩定
- 如果你是偏向 Application 監控或者是偏 API 效能的 Developer,建議可以追蹤 P99, P99.9, P99.99 這三條的變化,比較能夠反映出你的程式是否有特殊狀況
- 上班平時例行報告抓 P50 數字,臨時出事抓 P99 或更高數字比較好理解現在發生啥事
Q&A
Q1: 如果我臨時使用 ping 對特定服務做 RTT 量測,那他只有 avg. 呈現,那這樣準嗎?
$ ping www.microsoft.com.tw
PING microsoft.com.tw (20.112.52.29) 56(84) bytes of data.
64 bytes from 20.112.52.29 (20.112.52.29): icmp_seq=1 ttl=108 time=134 ms
64 bytes from 20.112.52.29 (20.112.52.29): icmp_seq=2 ttl=108 time=137 ms
64 bytes from 20.112.52.29 (20.112.52.29): icmp_seq=3 ttl=108 time=139 ms
64 bytes from 20.112.52.29 (20.112.52.29): icmp_seq=4 ttl=108 time=137 ms
^C
--- microsoft.com.tw ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 10238ms
rtt min/avg/max/mdev = 133.904/136.817/138.914/1.855 ms
A1: 以上面的數字來看,他的 P50 是 134,誠如上面講,看 avg. 不準,在網路相對穩定的狀況下,只能說有高度機會平均值近似於 P50,但你用 ping 工具目的不是真的要長期監控數據,主要是臨時網路除錯,譬如說抓爆 ping、或者是臨時收集一下網路狀況,以除錯來講是很好用的,所以大家還是可以加減用用