Kubernetes API 服務及跟各組件的交互關係
前陣子客戶那邊有個問題需要先了解 Kubernetes 從部署 Deployment 到實際上跟這些主要組件溝通的流程,不然很難進行 Troubleshooting (a.k.a. 觀落陰)。幸好本次研究有 3 位大大的一起參與 Max、地瓜、喜德,最終找到了一個跟現象毫無關係的根本問題 =_=,但因為過程算蠻難得的,特別記錄下來給大家參考參考
照例講個雜事,Red Hat OpenShift 4.6 (等同 Kubernetes 1.19) 要出啦!這是一個可以一路用到 2022 年 3 月 的版本,各位 Infra 不用在為了更新和升級落淚了 Q_Q,有興趣者可以參考 What's New in OpenShift Container Platform 4.6

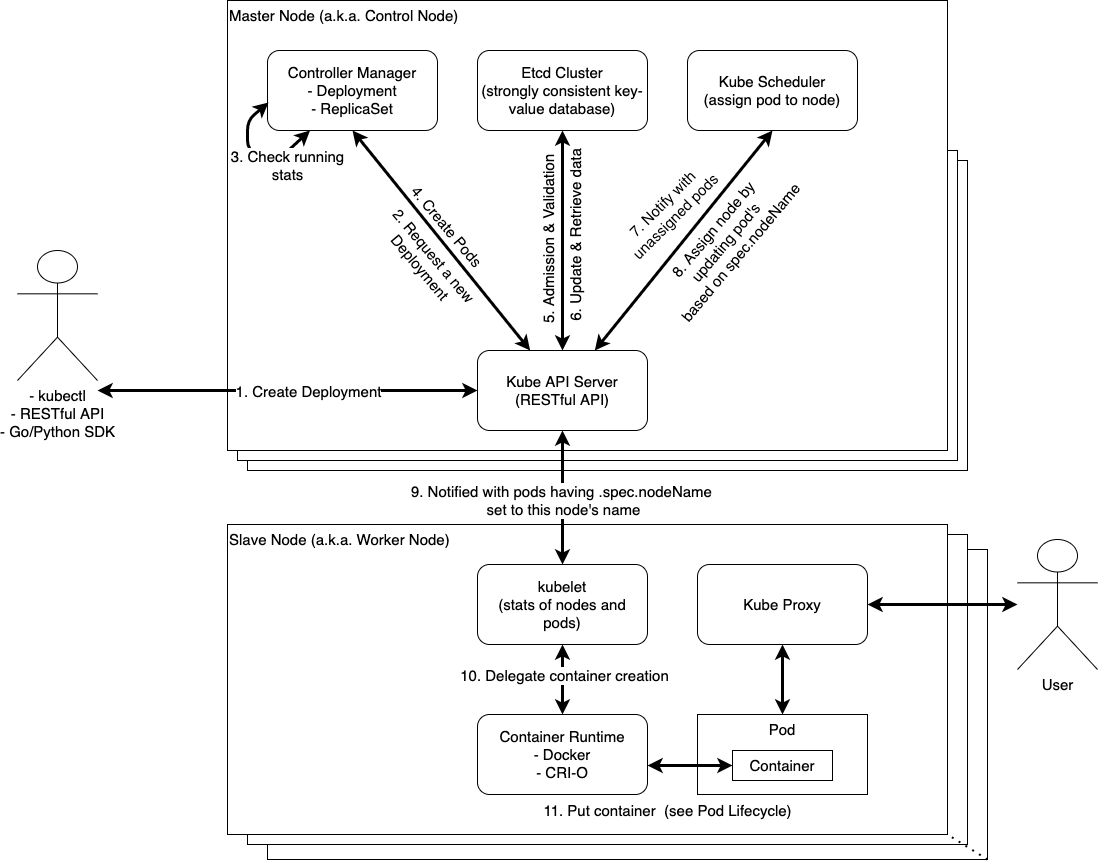
按照我個人對於 Kubernetes 內部溝通理解,約略分為下列 11 個溝通步驟,當然我知道再更細分的話,還可以分更多步驟出來,但我這圖僅針對 Container 最終能運行為主截止
如果有時候遇到一些不可知的神祕現象,可以思考一下整個系統,是位在哪一層卡住
Kubernetes Deployment 分解動作講解
- 使用者自行撰寫好或透過別人弄好的 Kubernetes YAML Generator 產生 Kubernetes Deployment YAML 檔案,且通过 Kubernetes API 访问集群一文所列的方式:kubectl / RESTful API / client-go / kubernetes-client/python 等方式發送到 Kubernetes API Server 宣告進行部署應用程式。這個階段 Kubernetes API Server 會進行依序是 Authentication、Authorization、Admission Control 等驗證和檢查語法,詳細過程可參考 Chapter 17. Admission Control and Authorization。如果都沒有問題的話,將會儲存 Deployment Object 至 etcd cluster
- 目前為止,Pod 還沒被啟動起來,但 Controller Manager 已經收到來自 Kubernetes API Server 的要求
- Controller Manager 會去檢查是否有數量正確的副本 (Replicas) 且對應正確需求的 Pod 已經在運行
- 如果沒有正確數量的副本正在運行,則會發送基於 Pod Spec 的要求到 Kubernetes API Server 請求建立對應數量的 Pod 起來
- Kubernetes API Server 寫入和讀取之前,會先經過兩關 Admission 和 Validation,前者 Admission 透過確認叢集全域設定來檢查是否可以新增或更新 Object,並可能依據叢集設定提供預設值,後者 Validation 則是在新增或更新過程中,來檢查傳入的 Object 是否合法,及是否僅包含有效參數,詳細可參考 Kubernetes Deep Dive: API Server – Part 2
- Kubernetes API Server 持續會對 etcd 所存放的 Kuberentes Object 進行更新或移除,詳細可參考 Kubernetes Deep Dive: API Server – Part 2
- 雖然 etcd 內部已經存有 Pod 的資訊,但不過僅僅是一條紀錄而已,現實狀況是還沒有分配到 Worker Node 上。這時候 Kubernetes API Server 會通知 Kubernetes Scheduler:目前有新增 Pod 的需求,並且還沒有 Worker Node 可以運行它
- Kubernetes Scheduler 會通過程式檢查現行資源使用狀況以及現有的 Pod 的分配,然後去計算出最適合擺放每ㄧ個新 Pod 的 Worker Node 位置。當決定出來之後,Kubernetes Scheduler 將會設定每一個 Pod 裡面的
spec.nodeName,將其轉換成 Worker Node 名稱 ,並將最終決定通知至 Kubernetes API Server 進行更新請求 - 直至本步驟為止,Pod 已經知道它應該要在哪一個 Worker Node 上面運行,但將通知位於需被分配的 Worker Node 上的 kubelet,並指示這些來自於 Kubernetes API Server 的新增 Pod 請求都應該要被 Kubelet 被遵照執行。然而,該 Worker Node 節點上的 Kubelet 將檢查自身是否已經將要運行的 Pod 運行起來。
- 一但 Kubelet 確定 Pod 應該要運行於該節點上之後,就會呼叫 High-Level Contianer Runtime (如: Docker、Containerd、CRI-O 等) 已啟動容器 (Container)。當一切都準備好之後,kubelet 會將其狀態報告回傳至 Kubernetes API Server
- 接下來就是依據 Pod Lifecycle - Kubernetes 所述,建立 infra (pause) container 後,開始將Pod Spec 所要求的 Container 一個一個拉取並且啟動,並且與 Kube-proxy 協作將服務轉發出去
Q&A
High-Level Container Runtime 跟 Low-Level Container Runtime 差異是啥?
Low-Level Container Runtime 主要專職運行容器或其特定環境,實際專案如,常見於各大專案的 runc 或者是 crun、runv 等,詳細可參考 opencontainers / runtime-spec - implementations.md
High-Level Container Runtime 主要負責管理各式容器映像檔以及負責跟 Low-Level Container Runtime 管理跟溝通,本身不處理實際運行容器的事情,一般都會有一個 Daemon 和 API 可以去監控底層狀態,譬如說 OpenShift 4 之後所使用的 CRI-O 或者是更多人比較知道 Dockerd 跟被拆分出來的 containerd 都同屬這類
文後感謝
感謝地瓜、Davy 兩位大大的半夜協助和毫不知情照片被我拿來用的 hwchiu
References
- Kubernetes deep dive: API Server - part 1
- Introduction to Kubernetes API - the way to understand the concept of Kubernetes Operators.
- Kubernetes Deep Dive: API Server – Part 2
- Kubernetes YAML Generator - Powered by Octopus.
- 通过 Kubernetes API 访问集群
- kubernetes/client-go
- kubernetes-client/python
- Chapter 17. Admission Control and Authorization
- Kubernetes Deep Dive: API Server – Part 2
- Podman: Managing pods and containers in a local container runtime
- Pod Lifecycle - Kubernetes
- What's New in OpenShift Container Platform 4.6
- opencontainers / runtime-spec - implementations.md