Red Hat OpenShift 4 的 etcd 之幾個你應該要知道的事之一
打從 OpenShift 4 之後,etcd 的安裝變成是透過 etcd-operator 來進行安裝的,預設狀況下一次會建立 3 個 etcd instances,然後把他們弄成一個 etcd cluster,本文會記錄一些關於 OpenShift 跟 etcd 之間的一些操作記錄
透過 oc 檢查 etcd 狀態
核心中的核心,正常狀態下一定是要好的,它的穩定性會直接關聯到 etcd 叢集的穩定性,兩點之間建議須低於 >100ms
$ oc get pods -n openshift-etcd -o wide | grep etcd
etcd-control-plane-0 3/3 Running 0 2d3h 10.0.97.1 control-plane-0 <none> <none>
etcd-control-plane-1 3/3 Running 0 2d3h 10.0.97.2 control-plane-1 <none> <none>
etcd-control-plane-2 3/3 Running 0 2d3h 10.0.97.3 control-plane-2 <none> <none>
檢查 etcd 叢集狀態
採用跟前一篇介紹的方法 Red Hat OpenShift Pod 與 Container 的愛恨情仇 進行 etcdctl 的基礎操作
$ oc rsh -n openshift-etcd etcd-control-plane-0
Defaulting container name to etcdctl.
Use 'oc describe pod/etcd-control-plane-0 -n openshift-etcd' to see all of the containers in this pod.
sh-4.2# etcdctl version
etcdctl version: 3.3.18
API version: 3.3
sh-4.2# etcdctl endpoint status -w table
+------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://10.0.97.1:2379 | 8e7cdeadd4c04bd3 | 3.3.18 | 168 MB | true | 109 | 35522525 |
| https://10.0.97.2:2379 | 65124c220e1d1efa | 3.3.18 | 168 MB | false | 109 | 35522525 |
| https://10.0.97.3:2379 | 23675b8f347a5bea | 3.3.18 | 168 MB | false | 109 | 35522525 |
+------------------------+------------------+---------+---------+-----------+-----------+------------+
sh-4.2# etcdctl endpoint health -w table
+------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+------------------------+--------+-------------+-------+
| https://10.0.97.3:2379 | true | 12.52718ms | |
| https://10.0.97.2:2379 | true | 16.830977ms | |
| https://10.0.97.1:2379 | true | 21.484222ms | |
+------------------------+--------+-------------+-------+
sh-4.2# etcdctl member list -w table
+------------------+---------+-----------------+------------------------+------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+-----------------+------------------------+------------------------+
| 23675b8f347a5bea | started | control-plane-2 | https://10.0.97.3:2380 | https://10.0.97.3:2379 |
| 65124c220e1d1efa | started | control-plane-1 | https://10.0.97.2:2380 | https://10.0.97.2:2379 |
| 8e7cdeadd4c04bd3 | started | control-plane-0 | https://10.0.97.1:2380 | https://10.0.97.1:2379 |
+------------------+---------+-----------------+------------------------+------------------------+
使用 etcdctl 原生效能檢查
承上,你也可以直接使用 etcdctl 做一個 60 秒的檢測,
sh-4.2# etcdctl check perf -w table
60 / 60 Boooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo! 100.00%1m0s
PASS: Throughput is 150 writes/s
PASS: Slowest request took 0.134647s
PASS: Stddev is 0.003738s
PASS
關於預設參數
透過 oc describe pod/etcd-control-plane-0 -n openshift-etcd 可知,
- ETCD 選舉超時預設時間 (ETCD_ELECTION_TIMEOUT): 1000ms
- ETCD 心跳間隔預設時間 (ETCD_HEARTBEAT_INTERVAL): 100ms
etcd 的分散式一致性協定仰賴上述 2 個參數來保證節點之間能夠在部分節點斷線的狀況下依然能夠正確處理 Leader Node 的選舉。
依據 etcd - tuning 及個人經驗可知,ETCD_HEARTBEAT_INTERVAL,即由 Leader 節點通知其他節點 它還是 Leader 的頻率,建議設定為 2 個節點之間 RTT 最大值時間 * 1 ~ 1.5 倍,若該值設定太短,etcd 會發送無用的心跳確認訊息,反而增加 CPU / Network / Disk 無謂的資源消耗;若該值設定太長,就會導致監控節點異常時間過長,會有重新選舉的事情發生。判斷 RTT 的最簡單方式就是使用 ping,如下
# 登入節點
$ oc debug node/control-plane-0
Starting pod/control-plane-0-debug ...
To use host binaries, run `chroot /host`
Pod IP: 10.0.97.1
If you dont see a command prompt, try pressing enter.
sh-4.2# chroot /host
sh-4.4# ping 10.0.97.5 -c60
PING 10.0.97.5 (10.0.97.5) 56(84) bytes of data.
64 bytes from 10.0.97.5: icmp_seq=1 ttl=64 time=0.191 ms
64 bytes from 10.0.97.5: icmp_seq=2 ttl=64 time=0.151 ms
64 bytes from 10.0.97.5: icmp_seq=3 ttl=64 time=0.213 ms
...omit...
64 bytes from 10.0.97.5: icmp_seq=59 ttl=64 time=0.142 ms
64 bytes from 10.0.97.5: icmp_seq=60 ttl=64 time=0.204 ms
--- 10.0.97.5 ping statistics ---
60 packets transmitted, 60 received, 0% packet loss, time 59000ms
rtt min/avg/max/mdev = 0.112/0.212/0.435/0.054 ms
如上面數字表現,RTT 測試出來是 0.435ms,遠低於預設值 100ms,所以就不用特別改
ETCD_ELECTION_TIMEOUT,則是表示如果節點等待多久沒收到 Leader 的心跳確認的話,就會開始嘗試去競選 Leader 的位子,建議設定為 2 個節點之間 RTT 最大值時間 * 10,以應對網路變化,故如果原有 RTT 為 100ms 的話,則選舉超時設定則為 1000ms。
另外選舉超時建議上限值為 50,000 ms,心跳間隔上限值為 5,000 ms
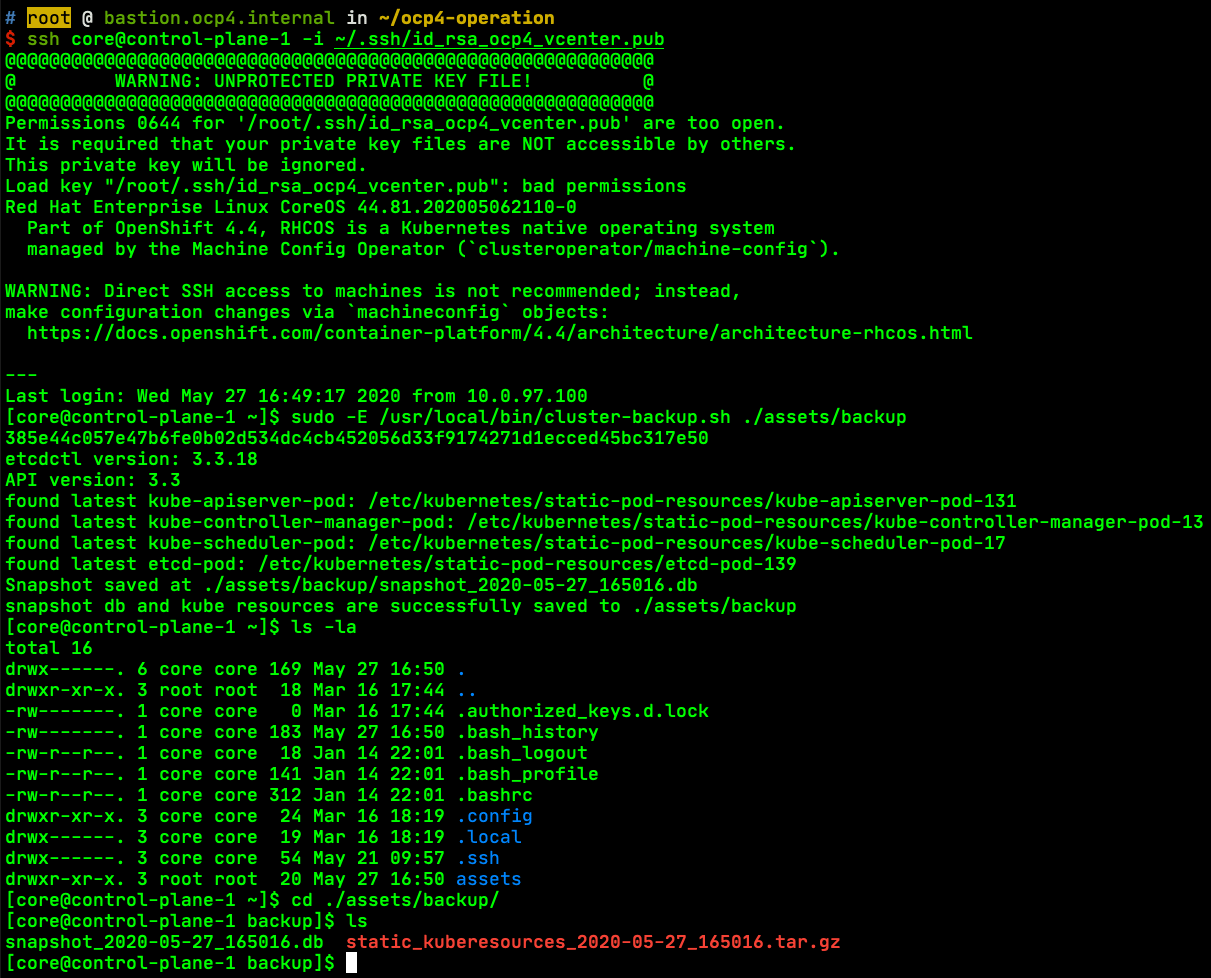
備份 etcd database
$ ssh core@control-plane-1 -i ~/.ssh/id_rsa_ocp4_vcenter.pub
Last login: Wed May 27 16:49:17 2020 from 10.0.97.100
# Backup
[core@control-plane-1 ~]$ sudo -E /usr/local/bin/cluster-backup.sh ./assets/backup
385e44c057e47b6fe0b02d534dc4cb452056d33f9174271d1ecced45bc317e50
etcdctl version: 3.3.18
API version: 3.3
found latest kube-apiserver-pod: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-131
found latest kube-controller-manager-pod: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-13
found latest kube-scheduler-pod: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-17
found latest etcd-pod: /etc/kubernetes/static-pod-resources/etcd-pod-139
Snapshot saved at ./assets/backup/snapshot_2020-05-27_165016.db
snapshot db and kube resources are successfully saved to ./assets/backup
# Check
[core@control-plane-1 ~]$ cd ./assets/backup/
[core@control-plane-1 backup]$ ls
snapshot_2020-05-27_165016.db static_kuberesources_2020-05-27_165016.tar.gz
# Copy to outside
[core@control-plane-1 backup]$ scp snapshot_2020-05-27_165016.db static_kuberesources_2020-05-27_165016.tar.gz [email protected]:~/
snapshot_2020-05-27_165016.db 100% 171MB 135.1MB/s 00:01
static_kuberesources_2020-05-27_165016.tar.gz 100% 64KB 56.1MB/s 00:00
有圖有真相
後話
下回待續